Find a post
Big Data
Featured
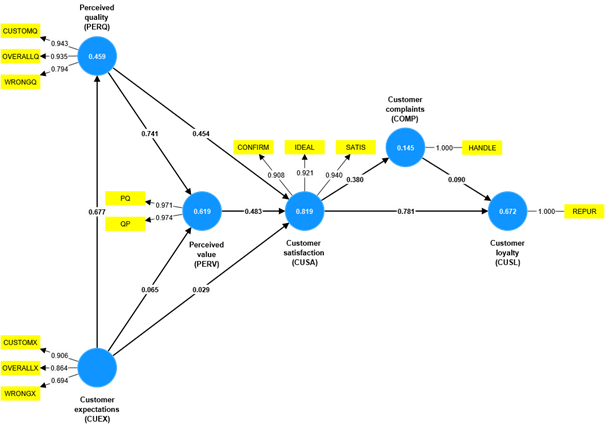

Data Literacy, Collecting Data from Electronic or Paper Documents, Big Data, Q3, August 2023, Quantitative Data Analysis
What do researchers need to know about using datasets?
Data Literacy, Collecting Data from Electronic or Paper Documents, Big Data, Q3, August 2023, Quantitative Data Analysis
Data Literacy, Collecting Data from Electronic or Paper Documents, Big Data, Q3, August 2023, Quantitative Data Analysis




Jump to

Sage Campus
Online learning for skills and research methods. Our 200+ hours of online courses are self-paced and instructor-led, comprising an engaging mix of Sage-quality content, video, interactives, and formative assessments.
Methods Minute Newsletter
Sign up to be the first to know about the latest news and events
Statistics
Blog















Tips with Diana
This popular series has now ended but you can catch up on all the posts here.



